僕にとってアジャイルは哲学で宗教だった
こんにちは、asatoです。
タイトル過激かな、そんなことないかな。 アジャイルは宗教か?みたいな話、最近見なくなりましたよね?
ここ一年、アジャイル開発初めてだったり始めたての方とお話していて、なにか自分が初めてアジャイル開発を実践したときと比べて違和感を感じたことを言語化したく。
自分が始めたときのアジャイルの捉え方を思い出す
僕が初めてアジャイル開発に出会ったのは2017年でした。それまでウォーターフォールで大規模基幹システムの開発をしてまして、部署異動でユーザー向けのWebシステムとかを作るようになったころ。先輩からの指令により『アジャイルサムライ』片手にスクラムを始めました。POとして。
『アジャイルサムライ』 を読んで、僕は思いました。
「あ、これは哲学で宗教だ」
すごくポジティブなことなので叩かないでください😀
『アジャイルサムライ』に書かれていることは、当時の自分には全て「普通のこと」に感じたんです。人間の物語としてどれも「普通のこと」でした。だけど今までの開発では「普通ではないこと」でした。
このとき、僕は「アジャイルは宗教なんだ」と思いました。それは「これが自分達を助けてくれるものだと強く信じて、これを強く実践しなければ、何も得られない」という直感でした。
そしてインセプションデッキを実践してみたり、スクラムイベントを実践する中で「アジャイルは哲学なのかも」という考えも浮かんできました。 唯一解がまるでない質問を投げかけられ、チームでそれに答える。正解がないのだから自分たちで自分たちの答えを信じるしかない。もっと良いプロダクトをつくるには、もっといいチームになるには。自分たちで答えのない問いを作って、苦しみながらチームの答えを出していく。考えの違い、目線の違いでイライラしたり衝突したりさながら、なんか最後は謎の満足感がある。
この時の経験が価値観を揺さぶって、開発に限らず考え方・捉え方が変わったと思う。残業よりも時間内に終わらせることがカッコよくなり、マルチタスクより一つに集中した方が効果的だと感じるようになったし、稼働より価値、個人プレーからチームビルディング、色々変わった。そしてそれは今の自分にとって「よかった」と思う。
僕にとって、アジャイルが哲学で宗教だったことが今の僕を良い方向に支えてくれている。
最近感じるギャップ
現代、2022年に戻ってきた。たかが5年くらいしか違わないのでわからないけど、アジャイル開発はさらに普及しているんだと思う。そして、界隈の方々の努力もあって、「アジャイルは宗教だ!」みたいな論争もなく、ちゃんと「メソッド」として受け入れられているように感じる。PMBOK7版とか盛り上がってましたよね。アジャイル〇〇みたいなのいっぱいあるし。
なので、これからアジャイル開発を実践するぞ!という人たちもちゃんとHowを学ぼうと躍起になっている。アジャイルはどうやってプロジェクトを成功に導いてくれるのか。何をすれば成功するのか。 スクラムガイドに書いてあったからスクラムイベントの時間枠を取る。その枠で今までやってきたミーティングをする。今まで作ってきた設計書に追加でバックログをつくる。インセプションデッキを作るらしいから、ドキュメントをつくる。
メソドロジー的な側面として、すごく正しいと思う。止まっていいプロジェクトも失敗していいプロジェクトも多分ない。
でもそこに感動はないのかもなと思ってしまう。あの時自分が感じた衝撃はなんだったんだろうか。どうやったら目の前の人にもあの時の感動のような影響を受けてもらえるだろう。
「アジャイルは哲学」「アジャイルは宗教」なんて今更言うつもりはないです。
でも、もし今あなたがアジャイル開発始めてみたけど、まぁこんなもんか、と感じているならば。
「アジャイルは哲学で宗教なのかもよ」
とお伝えしてみたい。
殴り書きをここまで読んでくださり、ありがとうございます。
とりあえず会おうの時代は終わったんだ
かつて、「とりあえず会おう」の時代があった。 会うことが始まりだった。会わないことには何も始まらなかった。会わないと何もわからなかった。
時代は令和。インターネットが当たり前の時代。 会う前から始まっている。お腹が空いたら美味しいと評判のお店を検索する。欲しいものはネットで情報を集め、買うとなれば最安値で買える場所を探す。マッチングアプリで会話を交わし、合いそうだと感じてから合う。
時代はコロナ禍。会わないことが当たり前の時代。 会うことはリスキーで、会わなくても済むように世界が進んでいる。
会うことは高価なことになってきている。「とりあえず会ってから」の時代は終わり、「会う価値があれば会う」時代に移り変わっているように感じる。
なんの話か。チームビルディングの話だ。
…
こんにちは。asatoです☀︎
コロナ禍。リモートワーク時代。みなさんのチームはビルディングできていますか? リモートワークでのチームビルディングを余儀なくされて、「リアルで会えるようになったら」と考えてる方や、リアルを強行されてる方もいらっしゃるのではないでしょうか。
「リアルで会う」ことはチームビルディングにとって有益なことは間違いないでしょう。同じ空間を共有し、ノンバーバルなコミュニケーションも取れ、不安定な通信も不慣れなツールも必要ない。人と接することはプラスに働くホルモンの分泌を促進し、仲間意識を育てる。
とりあえず集まって、自己開示して、チームのパーパス語り合って、雑談を交えながら、夜は飲みニケーション!! え、夜は自粛しろって?じゃあコロナが落ち着くまでは粛々と仕事しとこうな!!
違う…多分なんか違う…
インターネットが普及して、モノ・コトが溢れ、趣味嗜好も多様化したこの時代、僕たちは選択を余儀なくされています。何かを優先するために何かを犠牲にしています。選択肢も感知できないほどの量です。 リモートワーク環境が整理され、オフィスに行くかどうかも(選択のしにくさはあるにせよ)個人の自由です。
オフィスに行くのが当たり前の時代ではないでしょう。リモートで入社した人もいます。 オフィス近辺に住んでいない人もいます。満員電車に積極的に乗りたい人は少ないはずです。コロナは怖いです(個人的にはコロナにかかることでかかる迷惑も考えたい)。家族と過ごす時間を増やしたい。趣味に捧げる時間を増やしたい。家の仕事場環境が最強。
人によって色々な背景や想いがあります。 リアルでチームビルディングをするためには「リアルでチームビルディングをする」ことを他のメンバーに選択してもらわないといけない。
「リアルで会う」選択をしてもらえるようにメンバーに働きかけられているだろうか。 「とりあえず会う」時代は終わった。会う前から始まっている。他の選択肢より「リアルで会う」ことを選択してもらえるような関係をオンラインで築けているだろうか。築くために何をしているだろうか。
効果的にコミュニケーションできているかな。効果的に発信できているかな。効果的にリアクションとれているかな。効果的にツールを活用できているかな。自分と会いたいと思ってもらえる何かをしているかな。オンラインでもできることはまだないかな。オンラインだからこそできることもないかな。
あぁ、難しい。難しいけど、これがリアルだし当たり前はどんどん変わるんだよな。
片付けもせずに帰ります。ごめんなさい。笑
雑談会でリーンコーヒーでも
こんにちは。asatoです。
雑談会にリーンコーヒーを持ち込んだらとてもいい感じだったので、リーンコーヒーをご紹介です。
リーンコーヒーとは?
リーンコーヒーとはなにか。僕はこちらのスライドで知りました。😊
Lean coffee from Takeshi Arai
「アジェンダのないミーティング」と呼ばれているようです。
通常のミーティングでは、進行役などがアジェンダを作成し、目的やトピック、時間配分を予め設計していますよね。 それに対してリーンコーヒーは、参加者全員でその場でトピックを決め、短い時間でなるべく多くのトピックを議論します。
詳しい説明は↑のスライドを参照いただくとして、以下のようなかんたんな手順で議論を進めます。
- 参加者がそれぞれで今議論したいトピックを付箋に書き出す
- 自分の書いた付箋を簡単に紹介する
- 全員で議論したいトピックに投票する
- 投票数の多いトピックから7分ずつ議論する。7分過ぎてまだ話したい人が多ければ時間を追加する。少なければ次のトピックへ。
おぉ。なんか面白そう。
雑談盛り上がらない問題
リモートワークが増え、会議室足りない問題が解消され課題解決のコミュニケーションがしやすくなった一方、関係構築のコミュニケーションが減ってしまったと嘆く方は多いのではないでしょうか。 そのために「雑談」や「コーヒーブレイク」「ランチ会」などを模索しているチームも多いはず。
...
盛り上がっていますか??
...
僕は盛り上げられませんでした!
ランチ会をやっても誰も集まらず、雑談会を開いてももくもく会のようになる。
そりゃそうですよね。「なにか話したいことありますか?」とか言われても、そうそうない。
そこでリーンコーヒー
そこでリーンコーヒーを知って、試してみると盛り上がるようになったんですよ👏
リーンコーヒーで雑談会をやるメリットは以下のようなものがあるかなと思います。
- トピックを考えるもくもくタイムがあるので、集中して取り組める
- 実際に話すトピックは投票で決めるので、「みんな興味ない話を振っちゃうかも」の不安を解消できる
- 1トピック7分などの短い時間が決まっているので、盛り上がるか不安なトピックでも大丈夫な気持ちになれる
- 話すトピックとして選ばれなくても、それぞれがどんなことに興味関心があるのか垣間見える
- 次の雑談会のトピック案を日頃から気にするようになる
他にもあると思いますが、特に「話し始めて盛り上がらなかったらどうしよう」の不安を解消するのに役立つなぁと感じてます。
いろいろカスタマイズも
自分たちの雑談会スタイルに合わせてカスタマイズも可能ですよね。
例えば、トピックあたりの時間。10分でもいいですし5分でもいいですし、トピックごとに「○○分くれ!」と宣言してもいいですし。
僕たちも最初は10分で始めて、もっといろいろなトピック話したいねーと今は7分にしたりと調整してます。
例えば、最初に出すトピック案の数。
最初は無限でOKにしていましたが投票がバラけたり、いつもトピックが選ばれない人が出てしまったりしたので、「一球入魂トピック」としてとびっきりの1トピックを出してもらう日を作ったりしています。
ツールとか
オンラインであれば以下のツールでサクッとできます。
- Zoom
- Miro
Miroは予めブレストするための場所や付箋、投票アイコンなどを用意しておくとスムーズです。
トピックの継続投票はZoomの投票でやったりスタンプでやったりするとよいですね。
タイムキーパーは一人いるといいです。Miroの有料だとタイマーを共有できたりしますが、まぁ時間になったら話の良きタイミングでタイムキーパーが継続投票を促すといいですね。
まとめ
ということで雑談会でのリーンコーヒーがおすすめですって話でした。
リーンコーヒー、汎用性高いので、ふりかえりとか他の場面でも使えそうですよね。
Node, Puppeteer, Dockerでスクレイピングしてみる
こんにちは。asatoです。
スクレイピングというテクニックがあります。
Webサイトなどを解析してほしい情報を自動的に入手したりできるやつです。勉強がてらやってみたのでまとめです。
※ スクレイピングを悪用してはいけないです。サイトには負荷がかかります。利用規約で禁止しているサービスもあります。ご利用は計画的に。
なにする?
今回は自作プロダクト「spaces.bz」を題材に、Google検索で「spaces.bz」を検索してトップに表示されているかどうかをチェックするプログラムを組んでみようと思います。
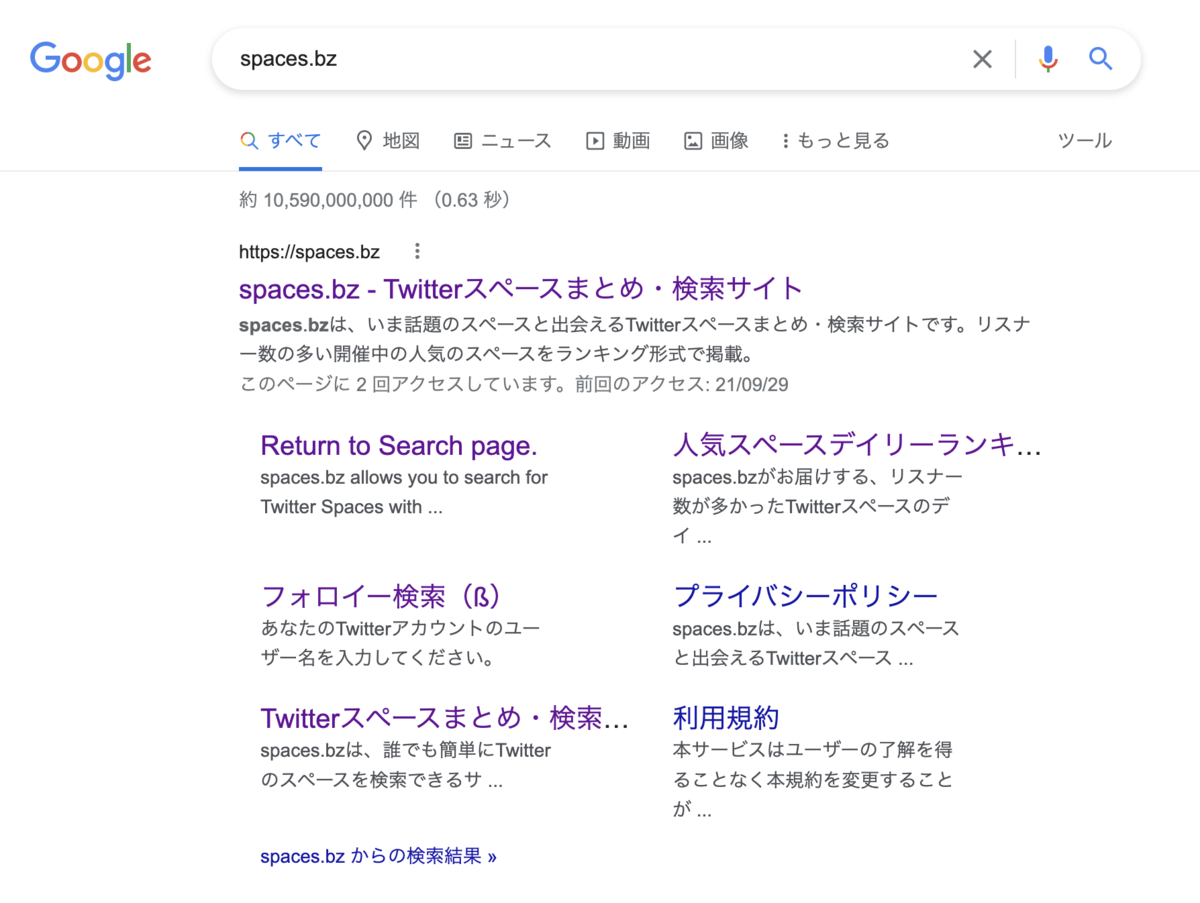
トップに出てきたら嬉しいですが、毎日手でやるのは面倒ですよね♪
アーキテクチャ
今回はNodeを使います。理由は僕が使い慣れているからです。
あと、Dockerも使います。理由は僕がローカルに色々入れたくないからです。
あと、画面操作やデータの取得はpuppeteerを使います。理由は前使ったことがあるからです。
あんまり理由がいい加減でごめんなさい。そんなに特殊な選択はしてないのでね。
一応バージョン情報。
- docker: 20.10.8
- node: 17.4.0
- puppeteer: 13.3.0
ローカルに入っているのはdockerだけです。あとはこれから入れてきますよー。
おおまかな手順
- puppeteerを動かすnodeコンテナをつくる
- スクレイピングのコードを書く
puppeteerを動かすnodeコンテナをつくる
Dockerfileとdocker-compose.ymlを作成します。
# Dockerfile FROM node WORKDIR /app VOLUME /app/node_modules RUN apt-get update \ && apt-get install -y wget gnupg \ && wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - \ && sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' \ && apt-get update \ && apt-get install -y google-chrome-stable fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-kacst fonts-freefont-ttf libxss1 \ --no-install-recommends \ && rm -rf /var/lib/apt/lists/* RUN yarn add puppeteer CMD ["node", "index.js"]
# docker-compose.yml version: "3" services: app: build: . volumes: - .:/app
Dockerfileの中でpuppeteerいれちゃいます。
DockerfileでRUN apt-get ~のところでchromeをインストールしてますね。
puppeteerのトラブルシューティングにかかれていますが、これをしないとpuppeteerがdockerコンテナの中でうまく動けません。
これでビルドしておけば、とりあえず環境の準備は完成です(≧∇≦)b
$ docker compose build
スクレイピングのコードを書く
環境が整ったのでスクレイピングのコードを書いてみます。
Dockerfileで起動時にnode index.jsのコマンドを実行するようにしているので、index.jsにコードを書いていきます。
# index.js const puppeteer = require('puppeteer') !(async() => { const browser = await puppeteer.launch({ args: [ '--no-sandbox', '--disable-dev-shm-usage' ] }) const page = await browser.newPage() // googleのトップページにアクセス await page.goto('https://google.com/') // 検索フォームに'spaces.bz'と入力 await page.type('input.gLFyf.gsfi', 'twitter spaces') // Enterキーを押下 await page.keyboard.press('Enter') // 検索結果が表示されるまで待つ await page.waitForSelector('cite.iUh30.tjvcx') // 検索結果トップのURLを取得 const topUrl = await page.$eval('cite.iUh30.tjvcx', el => el.innerText) // 検索結果トップが自分のサイトならOKメッセージ、違えばそのサイトのURLをコンソールに出力 if (topUrl === 'https://spaces.bz') { console.log('spaces.bzは検索トップに表示されています🎉') } else { console.log(`検索トップは「${topUrl}」です...`) } browser.close() })()
シンプルですね!コメントアウトも入れたので、それぞれの処理のイメージを掴んでもらえると嬉しいです。
具体的なpuppeteerの使い方は公式を御覧ください!色々できます。
さて、これを実行してみると...
$ docker compose up spaces.bzは検索トップに表示されています🎉
いえーい(≧∇≦)/
試しに検索キーワードを「twitter spaces」にしてみると...
$ docker compose up 検索トップは「https://help.twitter.com › ヘルプセンター › ツイート」です...
ぬーん(´・ω・`)
おわり
はい!Nodeでスクレイピングできました!
puppeteerも入っているのでUI操作も可ですね。
優しいスクレイピングライフを!
TestCafeのオプションをファイルで管理
こんにちは。asatoです。
TestCafeのオプションをコマンドで毎回書いていたのですが、Configuration fileなんてものがあったのか...
ファイルの適用
Configuration fileは.testcaferc.jsまたは.testcaferc.jsonの名前でワーキングディレクトリに置いておくと、testcafe実行時に自動的に読み込んでくれます。
--config-fileオプションを使えば、別の名前や別の場所に置いてあるファイルでも適用されます。
ファイルの中身
この記事では.testcaferc.jsを前提とします。
module.exports = { // options }
ベースはこちらで、optionsのところに必要なオプションを定義していきます。
おすすめオプション
オプションいっぱいあるんですが、現状こんな感じの定義をしてます。
module.exports = { browsers: "chrome:headless", screenshots: { takeOnFails: true, fullPage: true, thumbnails: false, }, concurrency: 3, stopOnFirstFail: true, cache: true, };
browsers
テストを実行するブラウザを指定します。複数のブラウザを設定したい場合は配列で指定します。
browsers: ["ie", "firefox", "chrome"]
詳しくは公式!
screenshots.takeOnFails
テストが失敗したときにスクリーンショットを自動的に撮影するかどうかです。デフォルトはfalse。
失敗の原因を調査するためにtrueにしてます。
screenshots.fullPage
スクリーンショットをページ全体で撮影するかどうかです。デフォルトはfalse。
screenshots.thumbnails
スクリーンショットのサムネイルを作成するかどうかです。デフォルトはtrue。
ただ僕は使っていないのでfalseに。ツールやサービスと連携して使っているとサムネイルが欲しくなったりするのかな?
concurrency
同時実行数です。ブラウザを何個起動するかですね。
この数を大きくすればテスト時間も短くなります。ただしリソースも必要になるので、環境に合わせていい感じの数に調整する必要があります。
stopOnFirstFail
テストが1つ失敗したタイミングで後続のテストを中断するかどうかです。デフォルトはfalse、つまり継続のテストもすべて実行するです。
僕は1つ失敗したらすぐに改修するってやり方が好きなのでtrueにしてます。CIで回すときも1つでも失敗したらどうせマージされないので、フィードバックをすぐに獲得するためにも、実行時間を抑えておくためにも、trueにしてます。
cache
スタイルシートやスクリプトをキャッシュするかどうかです。デフォルトはfalseです。
テスト実行時間短縮のため、trueにしてます。
まとめ
TestCafeのオプションをコンフィグファイルで管理してみました。 かなりいろいろと設定できますねー。
自分たちの開発スタイルに合わせて調整していきたいですね。
お財布に優しい個人開発の戦略 - spaces.bzの場合
こんにちは。asatoです。 Qiita Advent Calendar 2021 個人開発 3日目の記事です。
みなさん、今日も楽しく個人開発やってますか?? 個人開発は「楽しい」し「スキルアップ」できるし「夢(収益が出れば...)」もありますよね!
2021年9月、僕は友人とふたりでspaces.bzをリリースしました。 合言葉は「なるべく無料で...」。 そう、個人開発には潤沢な資金はありません!リリースしたはいいけどランニングコストだけかかって全然使われないは避けたいのです!
実際、spaces.bzは2021/12/3現在、支出は最初のドメイン代の3,000円のみです。 一方で、PV数は12000+/月、Twitterボットのフォロワー数は1,000+、それなりに利用してもらっているサービスになりました🎉
この記事では、spaces.bzがランニングコスト0で運営するためにとってきた戦略を紹介します。 お金が心配で個人開発やリリースをためらっている人たちの背中を押せれば嬉しいです。😁
spaces.bzとは?
今回開発をしたspaces.bzは、Twitter Spacesを検索したり、ランキングをまとめたりしているサイトです。 サイトの他にも、リスナー数の多いスペースをリアルタイムでお知らせするTwitter Botも提供しています。
spaces.bzは現在、月間12,000+PVくらいのプロダクトです。 大ヒット!のレベルではありませんが、毎日コンスタントにアクセスしていただいており、Botも2021年11月末現在で1,000+のフォロワー、僕たちとしてはちゃんと使ってもらえている実感を持てておりそこそこの達成感を得ています。
コストとしては、最初に友人こだわりのドメインを購入しているので3,000円がかかっていますが、その他はコスト0で運営しています。(僕たちの開発費はプライスレスです!💰)
全体のアーキテクチャは以下のようになっています。
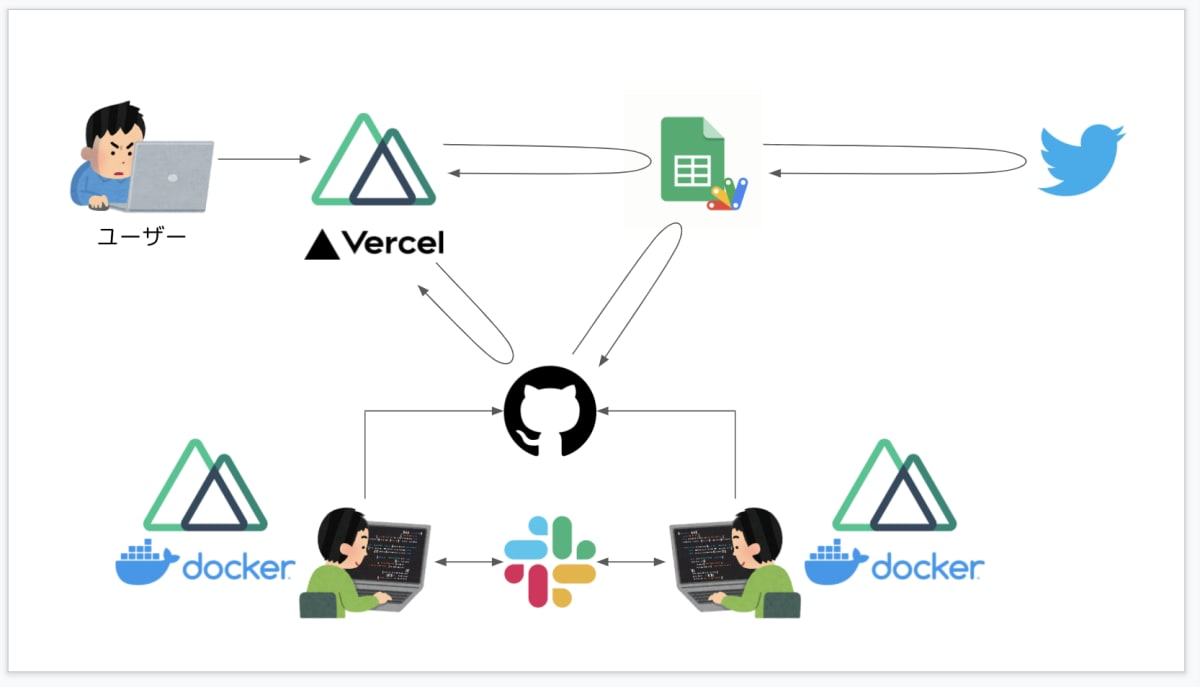
では、実際にどんなことを考えてspaces.bzをランニングコスト0で開発してきたのか、語っていきたいと思います。
戦略1:データを持たないプロダクト
僕たちが一番ネックに感じていたことが「データ」です。 なんとなく、ホスティングサービスに比べてデータベース系のサービスはちゃんと気をつけないと無料枠をすぐに食いつぶしてしまうイメージがあったんですよね。 データがないと面白いアイデアになりにくいと感じつつも、お財布を気にせずデータを保存する方法もあまり思いつかなかったからです。 そこでspaces.bzはAPIを活用するプロダクトの戦略をとりました。 APIであれば提供元のデータを活用して面白いことがやりやすそう、ってことです。 ちょうどTwitter社が2021年8月にTwitter SpacesのAPIを公開したこともあり、これを使って何か面白いことができないかと考えていったものがspaces.bzです。
Twitter APIは無料でも利用可能ですが、単位時間あたりのリクエスト数やツイート取得数に制限があります。 その制限の中でやりたいこととできそうなことのバランスをとりながらプロダクトを作ってきました。💪
戦略2:みんなが使っているサービスの拡張プロダクト
戦略1の付随効果ですが、spaces.bzはみんなが使っているTwitterを拡張するプロダクトになったことで独立したサービスよりも早い段階でユーザーを獲得できたと思います。 個人開発をしていて結局使われない...なんか変なところでお金かかるのも怖いから閉じよう...ってなることもあると思うのですが、その文脈ではすぐに見つけてもらい使ってもらうことができたことは個人開発をここまで継続できたモチベーションでした。
戦略3:無料でホスティング with Vercel
プロダクトを開発したらどこにホスティングするかは重要なテーマです。 spaces.bzは現在Vercelを利用しています。 個人利用では無料でホスティングができ、GitHubと連携することでpushを検知してBuild&Deployまでやってくれます。クレカ登録不要なのも何気に嬉しい😆。
もともとはNetlifyにホストしていたんですが、動的OGPをやりたいとなったときにSSGができるVercelに移行しました。(Netlifyでもpre-renderingを使って動的OGPをやる方法があるみたいですが、Netlifyはビルドの時間制限もあり移行を決行しました)
他にもGitHub PagesやHerokuなど、無料枠でも十分にホスティングできるサービスが充実しています。Build&Deployまでしてくれるサービスが多いですし、いろいろと調べて試して、自分のプロダクトにあったホスティングサービスを利用すれば、無料でプロダクトをリリースすることは難しいことではありません。
戦略4:無料でデータ管理 with Spreadsheet
戦略1と矛盾するのですが...笑
spaces.bzでは最初こそTwitter APIを叩くだけのプロダクトでサービスリリースをしたのですが、開発を重ねていく中でどうしてもTwitter APIを叩くだけでは実現できないやりたいことがでてきました。 しかし、最初に行ったとおり、データベースサービスの無料枠でやりくりできるか不安があったため、spaces.bzがとった戦略はGoogle Spreadsheetをデータベース代わりに使うことでした。
Spreadsheetにも5,000,000セルの制限があったりしますが、「見やすい」「使い勝手がわかる」「更新も楽」「すぐに使える」など、色々なメリットがあります。 Google App Script(GAS)の存在も大きいです。spaces.bzの場合、定期的にTwitter APIを叩いてデータを更新する処理が必要だったのですが、GASが大いに力を発揮してくれています。そしてGASとSpreadsheetは言わずもがな親和性が高い。 結果、今の段階ではSpreadsheet + GASで無料でデータベースを利用している状態をつくりだしています。
実現方法は別の記事を書いていますので、気になる方はどうぞ!
ちなみに最近は、スプレッドシートをほぼNoSQLのように使っており、1セルごとにJSONフォーマットでデータを打ち込んだりしています。 1セルは500,000文字制限があったりするので、それに気をつけながらやってみたところ、レスポンスが改善したりセル数制限の対策になったりしてます。🎉
戦略5:無料でCI/CD with GitHub Actions
開発をしているとCI/CD周りが気になりますよね。
特にspaces.bzは友人と2人で個人チーム開発を行っているので、テストやlintはCIでちゃんと回るようにしておきたい。今となってはデプロイはVercelがやってくれていますが、Netlifyを使っている頃はNetlifyにデプロイを任せるとすぐに無料枠のデプロイ時間を超過してしまいそうだったので、CIでビルドまで終わらせてデプロイだけをNetlifyでやることが必須でした。
CI/CDはGitHub Actionsで十分だと思います。パブリックレポジトリであれば制限なく、プライベートリポジトリでも2000分/月のワークフローを実行できます(Linuxの場合)。
僕たちはPRを作成したときにLintやテストを回し、mergeされたとき(mainにpushがあったとき)にデータの更新をしています。 割と高頻度に開発サイクルを回していますが、それでも2000分に達しないので、問題なく開発ができています。
戦略6:集客はBot
通常サービスを認知してもらうためには、色々なところで情報発信をしたりお金を出して広告を出したりしないといけませんよね。 人力 or お金の力の選択を迫られたりしますが、spaces.bzではそれをBotに任せる戦略をとりました。
待っていて流入があるほど甘くはないので、何かしら認知してもらわないといけない。けどお金は使いたくない。 そこでとった戦略が、リスナー数の多いスペースをお知らせするBot、です。 アカウントを見ていただくとわかるのですが、リスナー数が100, 500, 1000, ...などの区切りを達成したアカウントをお知らせするBotです。
もともとspaces.bzは「面白いスペースとの出会い」をコンセプトにしているので、そのビジョンから外れることなくサービスを認知してもらえるいい戦略になりました。
更に、ここでとったもう一つの戦略が3,000円で購入したドメインとサービス名です。 お気づきの方もいると思いますが、spaces.bzのサービス名はドメイン名と同じです。 そのため、Twitterなどで「spaces.bz」と入力すると「あ、URLね」と認識してくれて勝手に「http://spaces.bz」のリンクをはってくれます。 このおかげで、Botが「spaces.bzがお知らせします」とつぶやけばspaces.bzへの集客に繋げられるようになります。
最近はオーガニック検索の数も増えていますが、2021年11月末現在でspaces.bzの流入の80%がTwitterからです。 集客に使えそうなBotアイデアを考えることは、個人開発にとって重要なのです。
まとめ
いかがだったでしょうか? (ほぼ)無料で個人開発プロダクトを運営しているspaces.bzのここまでの戦略についてお話させていただきました! 少しでも個人開発を始めたい人の背中を押せていたら嬉しいです。
余談ですが、最近Twitter APIも盛り上がりそうな雰囲気を出していますよね。 いままで500,000tweets/月だったツイート取得上限が2,000,000に緩和されたり、APIのv2化をきっかけに機能が追加されたり。 面白いアイデアを世に出すチャンスかもしれないですね〜。
最後に宣伝
spaces.bz、ぜひ使ってみてください!
フィードバックはこちらから!
応援はこちらから!
Google SpreadsheetとGoogle Slidesでお手軽動的OGP with Nuxt
こんにちは。asatoです。
いま面白いスペースに出会えるspaces.bzでは、デイリーランキングで動的OGPを実装しています。
こちらのページからスペースをシェアすると画像が表示されます。
Twitterアカウントでは毎日ランキングを発表しているので、こちらでも確認できます〜。
実はこれ、Google SpreadsheetとGoogle Slidesを使って、GASで毎日OGP画像を生成して表示させているんです。 結構面白いアイデアかな、と思うのでシェアします!😊
全体像
まずこの記事で紹介する全体像を。
- 動的OGPのもとになるSlidesを作成
- 動的OGPのデータのもとになるSpreadsheetを作成
- GASを作成
- SpreadsheetのデータをもとにSlidesの文字列を置換
- Slidesを画像ファイルでエクスポートしてDriveに保存
- SpreadsheetにDriveに保存した画像ファイルのIDを追加
- Slidesを元の文字列に置換し直す
- SpreadsheetをWebApp(API)で公開
- Nuxtアプリで動的OGPを設定
ちょっと長いですが、お付き合いいただけると嬉しいです🙏
1. 動的OGPの元になるSlidesを準備
まずはいい感じのOGPのデザインをGoogle Slidesで作ります。

Coolです。ポイントとしてはOGPは1200mmx628mmのサイズがよいので、「ファイル > ページ設定」からスライドの縦横サイズを変更してます。
このスライドに書いている「name」はこの後置換するためのキーワードになってます。
2. 動的OGPのデータのもとになるSpreadsheetを準備
「name」を置換していきたいので、そんな感じのSpreadsheetを用意します。 spaces.bzの場合は、その日のランキング10位までをGASで集計して、そのデータを元に置換を行っています。 今回は簡単な例なので、以下のようなシートを用意します。
| id | name | ogpId |
|---|---|---|
| 1 | Test A | |
| 2 | Test B | |
| 3 | Test C |
ogp_idは今のところ空ですが列だけ用意しておきます。後でGASでOGP画像のファイルを生成したときに画像ファイルのIDをセットするカラムです。
3. GASを作成
この記事の佳境です!
まずコードの全容をさらします。 説明しやすいように書いていますが、内容を理解いただければ色々な書き方があるかなーと思います。
function main() { const ss = SpreadsheetApp.openById('<SpreadsheetのID>') const sheet = ss.getSheetByName('<Sheetの名前>') const data = sheet.getDataRange().getValues() const columnNames = data.shift() const presentationId = '<SlidesのID>' const folder = DriveApp.getFolderById('<FolderのID>') data.forEach((row, index) => { const name = row[1] replaceText(presentationId, name) const ogpId = downloadImage(presentationId, `${index}.png`, folder) row[2] = ogpId resetText(presentationId, name) }) data.unshift(columnNames) sheet.getRange(1, 1, data.length, data[0].length).setValues(data) } function replaceText(presentationId, name) { const presentation = SlidesApp.openById(presentationId) const slide = presentation.getSlides()[0] slide.replaceAllText('name', name) presentation.saveAndClose() } function downloadImage(presentationId, fileName, folder) { const presentation = SlidesApp.openById(presentationId) const slide = presentation.getSlides()[0] const slideId = slide.getObjectId() const url = `https://docs.google.com/presentation/d/${presentationId}/export/png?id=${presentationId}&pageId=${slideId}` const options = { headers: { Authorization: `Bearer ${ScriptApp.getOAuthToken()}` } } const response = UrlFetchApp.fetch(url, options) const image = response.getAs(MimeType.PNG) image.setName(fileName) const file = folder.createFile(image) return file.getId() } function resetText(presentationId, name) { const presentation = SlidesApp.openById(presentationId) const slide = presentation.getSlides()[0] slide.replaceAllText(name, 'name') presentation.saveAndClose() }
少し長いですが、少しずつ区切ってみていきます。
3-1. 各種変数の設定
const ss = SpreadsheetApp.openById('<SpreadsheetのID>') const sheet = ss.getSheetByName('<Sheetの名前>') const data = sheet.getDataRange().getValues() const columnNames = data.shift() const presentationId = '<SlidesのID>' const folder = DriveApp.getFolderById('<FolderのID>')
最初のconstたちは変数の設定です。
| 変数 | 説明 |
|---|---|
ss |
2で作成したSpreadsheet。<SpreadsheetのID>はhttps://docs.google.com/spreadsheets/d/<この部分>/edit |
sheet |
2で作成したシート |
data |
sheetのデータをArrayで取得したもの |
columnNames |
dataの1行目を取り出したもの |
presentationId |
1で作成したSlidesのID。https://docs.google.com/presentation/d/<この部分>/edit#slide=id.p |
| folder | 作成したOGP画像を格納しておきたいGoogle Driveのフォルダ。<FolderのID>はhttps://drive.google.com/drive/u/0/folders/<この部分>。このフォルダは公開設定にしておきます(後述) |
このとき、dataとcolumnNamesは以下のようになっています。
data = [ ['1', 'Test A', ''], ['2', 'Test B', ''], ['3', 'Test C', ''] ] columnNames = ['id', 'name', 'ogpId']
3-2. 置換して画像保存して置換し直す
data.forEach((row, index) => { const name = row[1] replaceText(presentationId, name) const ogpId = downloadImage(presentationId, `${index}.png`, folder) row[2] = ogpId resetText(presentationId, name) })
ここが核です!なにか色々やっているようですが、ほとんどの行は別に作成した関数を呼び出しているのでそこも説明していきます。
まず、全体はdata.forEachで回しています。
最初にrow[1]で、Test A, Test B, Test Cをループごとにnameに格納しています。
それに続いて、
- スライドのテキストを
nameに置換(replaceText()) - スライドをイメージ保存(
downloadImage()) - 保存したファイルのIDを
dataに追加(row[2] = ogpId) - スライドのテキストを置換し直す(
resetText())
と処理を流しています。
3-2-1. スライドのテキストを置換
スライドのテキストの置換処理を行うreplaceText()関数を定義しました。
function replaceText(presentationId, name) { const presentation = SlidesApp.openById(presentationId) const slide = presentation.getSlides()[0] slide.replaceAllText('name', name) presentation.saveAndClose() }
引数はpresentationIdと、置換後の文字列nameです。
まず、SlidesApp.openById(presentationId)で置換したいスライドがあるSlidesを開きます。
そして、getSlides()[0]を使って、そのSlidesの1枚目のスライドを取得します。
そのslideに対してreplaceAllText()を実行することで、slideの中の'name'の文字列を引数のnameに置換しています。
最後にpresentation.saveAndClose()で置換を確定しています。saveAndClose()を行わないと、次のイメージ保存で置換前の状態で保存されてしまうので要チェックです。
置換の処理はこれだけです。置換したい文字列が複数ある場合でも同じやり方でslide.replaceAllText()を追加すればできますし、複数のスライドに対してやりたい場合はpresentationに対してreplaceAllText()したり、getSlides()の結果をforEachで回してスライド1枚ずつに処理することで実現できますね。
3-2-2. スライドを保存
これで動的OGPのイメージの準備ができたので、これをイメージファイルに保存します。今回はpngで。
function downloadImage(presentationId, fileName, folder) { const presentation = SlidesApp.openById(presentationId) const slide = presentation.getSlides()[0] const slideId = slide.getObjectId() const url = `https://docs.google.com/presentation/d/${presentationId}/export/png?id=${presentationId}&pageId=${slideId}` const options = { headers: { Authorization: `Bearer ${ScriptApp.getOAuthToken()}` } } const response = UrlFetchApp.fetch(url, options) const image = response.getAs(MimeType.PNG) image.setName(fileName) const file = folder.createFile(image) return file.getId() }
何をするかというと、SlidesをダウンロードするURLにリクエストを投げて、レスポンスをpngファイルにして保存しようというやり方です。
引数は、presentationIdとfolder、そしてファイル名としてfileNameを取ります。
最初のpresentationとslideの式はreplaceText()と同じなので説明は省略します。
slideIdはそのスライドのIDのことで、https://docs.google.com/presentation/d/<presentationId>/edit#slide=id.<'この部分'>です。これはslide.getObjectId()で取得ができます。
これらの変数を使ってリクエストURL urlを作ります。
リクエストには認証が必要なので、ScriptApp.getOAuthToken()を使ってBearer認証できるようにoptionsを作っておきます。
このurlとoptionsを使って、UrlFetchApp.fetch()でリクエストを投げ、レスポンスをresponseに格納しています。
responseはHTTPResponseというClassになっているので、画像ファイルとして扱えるようにgetAs(MimeType.PNG)でpngファイルに変換し、setName()でファイル名を設定しました。
それを、folder.createFile()でfolderにファイルとして保存しているって流れです。
最後に、保存したファイル fileのIDをgetId()で取得して、返り値にしています。
3-2-3. 保存したファイルのIDをデータに追加
const ogpId = downloadImage(presentationId, `${index}.png`, folder) row[2] = ogpId
先程説明したようにdownloadImage()は作成したpngファイルのIDをreturnしてます。
それをrow[2]、つまりogpIdのカラムに設定しています。
詳しくは後ほど紹介しますが、これがNuxtアプリでGoogle Driveの画像ファイルをOGPに設定する肝だったりします。
3-2-4. スライドのテキストを置換し直す
ここまで終わったら次のループのためにスライドの文字列を元の'name'に戻しておきます。このためにresetText()の関数を用意して呼び出しています。
function resetText(presentationId, name) { const presentation = SlidesApp.openById(presentationId) const slide = presentation.getSlides()[0] slide.replaceAllText(name, 'name') presentation.saveAndClose() }
やっていることはreplaceText()の逆なので説明は省略!
3-3. スプレッドシートのogpIdを更新
data.unshift(columnNames) sheet.getRange(1, 1, data.length, data[0].length).setValues(data)
最後にSpreadsheetのogpIdカラムを更新しましょう。
すでにここまでの処理でdataの各Array要素の3つ目の要素にogpIdが格納されているので、Spreadsheetを上書きすればOKですね。
ということで、data.unshift(columnNames)でdataの1つ目の要素に列の名前を戻して、
sheet.getRange().setValues()でデータを上書きしています。
ここまでで画像を作成するステップが完了です。😊 ここからはSpreadsheetをもとにNuxtアプリでOGP画像を動的に設定してみましょう!
4. SpreadsheetをWebApp(API)で公開
次は先程OGPのIDを追記したSpreadsheetをWebAppで公開していきます。 このやり方は、以前に記事を書いたので詳細はそちらを見てください!
GASのコードは以下のようになります。先程のコード.jsに追記していきましょう。
... function doGet() { const users = getUsers() return ContentService .createTextOutput(JSON.stringify(users)) .setMimeType(ContentService.MimeType.JSON) } function getUsers() { const ss = SpreadsheetApp.openById('<SpreadsheetのID>') const sheet = ss.getSheetByName('<シート名>') const table = sheet.getDataRange().getValues() const keys = table.shift() const users = table.map((row) => { const object = {} row.map((value, index) => { object[String(keys[index])] = String(value) }) return object }) return users }
これを、デプロイしてWebApp公開しましょー。
5. Nuxtアプリで動的OGPを設定
まずは、Nuxtアプリで先程公開したWebAppにリクエストする下準備をします。今回はaxiosを使うことを前提として、serverMiddleware経由でWebAppを呼び出します。 こちらも先程の記事に詳細を載せております!
以下の更新、もしくは新規作成を行います。
# nuxt.config.js export default { ... + axios: { + proxy: true, + }, + serverMiddleware: [ + '@api/' + ], ... }
# api/index.js const express = require('express') const axios = require('axios') const app = express() app.get('/', async (req, res) => { const response = axios.get('<WebAppのURL>') res.send(response.data) }) module.exports = { path: '/api/', handler: app, }
これで下準備が完了です。あとはpagesのファイルでfetch()で情報取得して、head()で画像のパスを指定してあげるだけです。
今回はpages/index.vueでクエリパラメーターidに応じてOGP画像を出し入れしましょう。パスパラメーターとかでもやり方は基本的に変わりないです。
# pages/index.vue ... <script> export default { async fetch() { this.users = await this.$axios.$get('/api') const user = this.$route.query.id ? this.users.find((user) => user.id === this.$route.query.id) : null this.ogpUrl = user ? `https://drive.google.com/uc?export=view&id=${user.ogpId}` : <共通のOGPイメージのパス> }, data() { return { users: [], ogpUrl: null, } }, head() { return { meta: [ { hid: 'og:image', property: 'og:image', content: this.ogpUrl } ] } } } </script> ...
例えばこんな感じ。(nuxt.config.jsで他のタグは設定されている前提です!)
fetch内でクエリパラメーターidが存在する場合は、usersから同じidのuserを探してます。
見つかったらogpUrlにhttps://drive.google.com/uc?export=view&id=${user.ogpId}を、存在しない場合は<共通のOGPイメージのパス>をセットし、head()でog:imageのpropertyとしてogpUrlを設定しています。
こうすることでクエリパラメーターidに応じて動的にOGPを設定することができます。
さて、ここで出てきたhttps://drive.google.com/uc?export=view&id=です。
Google Drive上で画像ファイルを見ようとするとプレビューモードで表示されると思います。この状態ではコードからすれば画像ファイルとして扱うことができません。
実はhttps://drive.google.com/uc?export=view&id=<表示したい画像ファイルのID>であれば、プレビューモードではなく画像ファイルとして認識させることができます。
また、これで表示できるのは閲覧権限をもつユーザーのみですので、OGP画像を保存しているフォルダはすべてのユーザーに閲覧権限で公開されている必要があります。
ngrokで公開し、Twitter Card ValidatorでOGPが正しく設定されているか確認してみましょう。
id=1のとき

id=2のとき

動的にOGP画像が表示されてることを確認できました!
まとめ
長くなってしまいましたが、これでSpreadsheetとSlidesを使ってOGP画像を生成しNuxtアプリで動的OGPを実現する一連の流れを紹介させていただきました。 かなり色々なサイトを参考にさせていただいてここまでできたので、この場を借りてお礼を。m( )m GAS、かなり色々なことができるので楽しいですね。
参考
- Slides Service | Apps Script | Google Developers
- Spreadsheet Service | Apps Script | Google Developers
- Drive Service | Apps Script | Google Developers
- [Google Apps Script]Googleスライドのプレゼンテーションを他形式に変換する | 初心者備忘録
- Google ドライブでファイル名とリンクの一覧をお手軽に取得する方法 | DevelopersIO
- Google Drive に保存した画像を直接呼び出せるURLの取得 - Qiita